Retour vers le perceptron - fabrication d’un neurone synthétique à base de composants électroniques analogiques simples Back to the perceptron - building a synthetic neuron from simple analog electronic components
Jean-Christophe ORLIANGES ,
Younes El Moustakime ,
Aurelian Crunteanu STANESCU ,
Ricardo Carrizales Juarez
et Oihan Allegret
Les avancées récentes dans le domaine de l'intelligence artificielle (IA), en particulier dans la reconnaissance d'images et le traitement du langage naturel, ouvrent de nouvelles perspectives qui vont bien au-delà de la recherche académique. L'IA, portée par ces succès populaires, repose sur des algorithmes basés sur des "réseaux de neurones" et elle se nourrit des vastes quantités d'informations accessibles sur Internet, notamment via des ressources telles que l'encyclopédie en ligne Wikipédia, la numérisation de livres et de revues, ainsi que des bibliothèques de photographies. Si l'on en croit les propres dires du programme informatique ChatGPT, son réseau de neurones compte plus de 175 millions de paramètres. Quant à notre cerveau, qui était le modèle initial de cette approche connexionniste, il compte environ 86 milliards de neurones formant un vaste réseau interconnecté... Dans ce travail, nous proposons une approche plus modeste de l'IA en nous contentant de décrire les résultats que l'on peut obtenir avec un seul neurone synthétique isolé, le modèle historique du perceptron (proposé par Frank Rosenblatt dans les années 1950). C'est un "Retour vers le futur" de l'IA qui est entrepris pour fabriquer et tester un neurone artificiel à partir de composants électroniques simples. Celui-ci doit permettre de différencier un chien d'un chat à partir de données anatomiques collectées sur ces animaux.
Recent advances in artificial intelligence (AI) in the fields of image recognition and natural language processing are opening up new horizons that extend far beyond the realms of research, to influence our entire society. AI, which is associated with these popular successes, relies on algorithms based on "neural networks" which, using the vast quantities of information accessible via the Internet (information linked to the free encyclopedia Wikipedia, to the digitization of books and magazines, to the libraries of photographs available...), enable these systems to learn automatically. According to the ChatGPT computer program, its neural network contains over 175 million parameters. As for our brain, which was the initial model for this connectionist approach, it comprises some 86 billion neurons forming a vast interconnected network... In this work, we propose a more modest approach to AI, contenting ourselves with describing the results that can be obtained with a single isolated synthetic neuron, the historical perceptron model (proposed by Frank Rosenblatt in the 1950s). It's a "Back to the future" of AI that is undertaken to build and test an artificial neuron from electronic components.
Introduction
Les récents progrès de l'intelligence artificielle (IA) dans les domaines de la reconnaissance d'images, de la traduction de textes et du traitement du langage naturel ouvrent des horizons nouveaux, s'étendant bien au-delà du domaine de la recherche institutionnelle pour exercer une influence sur l'ensemble de notre société. Ces avancées impactent notamment notre façon de communiquer avec les machines, de travailler, de se déplacer, de recevoir des soins médicaux et même de dispenser l'enseignement. L'IA, qui bénéficie du succès croissant de ces réalisations populaires, tire profit d'algorithmes fondés sur des "réseaux de neurones". Ces réseaux exploitent la richesse considérable d'informations offerte par Internet, comprenant des données provenant de sources variées telles que la vaste base de connaissances de Wikipédia, la numérisation de livres et de revues, ainsi que des bibliothèques de photographies… L'apprentissage automatique de ces systèmes repose sur l'utilisation de ces quantités massives d'informations.
Dans cette étude, nous adoptons une démarche plus modeste en matière d’IA, nous nous contentons de décrire les résultats pouvant être obtenus au moyen d'un seul neurone synthétique isolé, en nous inspirant du modèle historique du perceptron, proposé par Frank Rosenblatt dans les années 1950. Une sorte de « Retour vers le futur » de l'IA est entreprise, consistant à concevoir et tester un neurone artificiel en utilisant des composants électroniques analogiques élémentaires. L'objectif de notre perceptron analogique sera de parvenir à distinguer un chien d'un chat à partir de données anatomiques collectées sur des images.
Le travail, présenté ci-après, a été réalisé dans le cadre du stage « Cordée de la recherche » de Younes El Moustakime alors étudiant en Master 1 EUR-IXEO à Limoges.
1. Contexte de l’émergence des réseaux de neurones artificiels
- Note de bas de page 1 :
-
Le terme d’intelligence artificielle est difficile à définir sans ambiguïté, les contours de cette « discipline » étant en constante évolution, ils varient suivant l’efficacité et la nouveauté des solutions algorithmiques proposées (Le Cun 2019).
Datant de plus de 60 ans, le concept d’intelligence artificielle fut formalisé à l’initiative de quatre éminents scientifiques : John Mc Carthy, Claude Shannon, Marvin Minski et Nathaniel Rochester (Mc Carthy 1955). Ceux-ci ambitionnaient la réalisation de tâches considérées comme « intelligentes » par des machines de façon plus efficace que l’être humain n’est capable de le faire1.
La mise en application de ce principe fondateur conduisit au développement de deux approches fondamentalement opposées et rivales : une approche « symbolique » logique totalement conceptualisée et une approche « connexionniste » s’appuyant sur les réseaux de neurones artificiels (RNA) dont le fonctionnement est non explicite, de type « boite noire » (Larousserie 2018).
L’approche connexionniste, avec ses solutions neuro-inspirées, a suscité beaucoup d’espoir à son lancement mais a rapidement montré ses limites pour les fonctions de reconnaissance et de tri des données (Minsky 1969).
Le retour en grâce des réseaux de neurones, à la fin des années 80, trouve son origine dans le travail de Yann Le Cun au sein du prestigieux laboratoire américain AT&T Bell (Lecun 1989). Celui-ci entreprend de résoudre le problème de la lecture automatisée des codes postaux apposés sur les colis. En tirant parti des données fournies par l'US Postal Service, il parvient à entrainer un réseau multicouche d'une efficacité remarquable, propulsant ainsi cette approche à une échelle industrielle (Cardon 2018).
Mais ce n’est que depuis 2011, que cette voie de recherche connaît une renaissance éclatante pour le traitement des masses de données avec l’exemple emblématique du triomphe de l’approche connexionniste, portée par une équipe dirigée par Geoffrey Hinton (A Krizhevsky 2012) lors de la conférence ECCV, pour la reconnaissance d’images de la base de données « ImageNet » écrasant les résultats obtenus par les approches « conventionnelles » (Cardon 2018). Le taux d’erreurs de reconnaissance est alors passé de 25 % à 16 % avec ces RNA dits convolutifs.
La figure 1 illustre l’explosion du nombre de paramètres utilisés dans ces algorithmes pour accroître leur capacité d’apprentissage. Le critère retenu dans cette représentation est l’estimation du nombre de neurones modélisés afin de comparer celui-ci au nombre approximatif de neurones dans le système nerveux de divers animaux (allant d’un jusqu’à l’éléphant).
Les premiers algorithmes utilisant des RNA étaient exécutés sur des ordinateurs conventionnels mais l’architecture fondamentalement séquentielle de ces derniers s’avère peu efficace pour implémenter ces réseaux interconnectés et procéder à leur apprentissage, dès lors que leur taille et le nombre de données d’apprentissage augmentent. Parmi ces limites intrinsèques, l’efficacité de ces machines est confrontée au « goulot d'étranglement de Von Neumann », liée à la séparation physique, dans les ordinateurs, de la mémoire et des unités de calcul induisant une latence pour chaque accès mémoire.
Après l’avènement de ces RNA, une recherche très active a alors été initiée pour construire des machines à leur image, d’architecture fondamentalement parallèle, qui seraient à la fois plus efficaces et plus sobres énergétiquement pour effectuer la phase d’apprentissage.
- Note de bas de page 2 :
-
Les algorithmes d’apprentissage profond sont actuellement exécutés grâce à des processeurs graphiques (GPU) plus efficaces pour cette tâche que les microprocesseurs (Lecun 2019)
La figure 2 présente une illustration des solutions « hardwares » proposées, en fonction du nombre de neurones accessibles2.
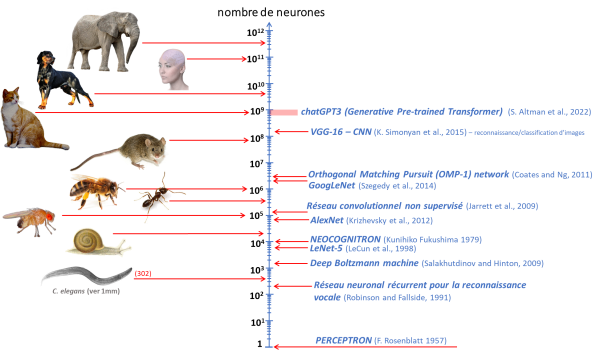
Figure 1 Comparaison du nombre approximatif de neurones dans le système nerveux d’animaux avec le nombre de neurones artificiels utilisés dans différents algorithms (softeware) développés depuis les débuts de l’approche « connexioniste » (d’après les données issues de Goodefellow 2016).
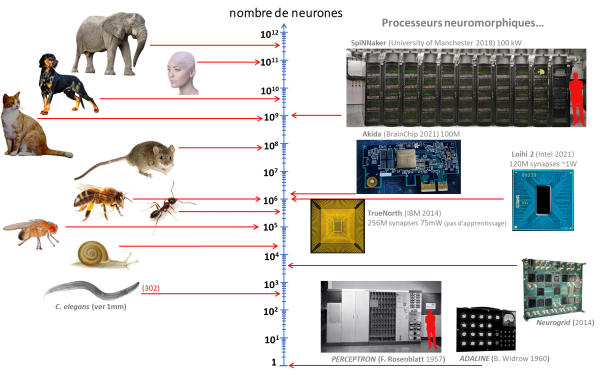
Figure 2 Comparaison du nombre approximatif de neurones dans le système nerveux d’animaux avec le nombre de neurones artificiels dans des dispositifs neuromorphiques physiques (hardware) (d’après les données issues de Wikipedia).
2. Le modèle du perceptron et sa fabrication avec des composants électriques analogiques simples
2.1. Le principe du perceptron
Le perceptron est un modèle (et une machine) créé à la fin des années 1950 par le psychologue américain Frank Rosenblatt de l’Université de Cornell. Il s’appuie sur la compréhension contemporaine des mécanismes du fonctionnement d’un neurone isolé (figure 3-a) et leur modélisation mathématique proposée quelques années plus tôt par McCulloch et Pitts (McCulloch 1943). Comme illustré sur la figure 3-b, le neurone « mathématique » calcule la somme des signaux amonts (X1, X2, X3…), chacun étant affublé d’un poids spécifique relatif à son importance (W1, W2, W3…). Si la somme de ces activités, une fois pondérées, est inférieure à un certain seuil prédéfini, le neurone reste inactif. En revanche, si cette somme dépasse ce seuil, le neurone s'active (comme illustré sur la figure 3-b).
A ce neurone formel, Rosenblatt ajoute une procédure d’apprentissage à partir de l’estimation de l’erreur commise lors de l’essai ce qui permet l’ajustement des poids synaptiques par correction d’erreur (Rennard 2013).
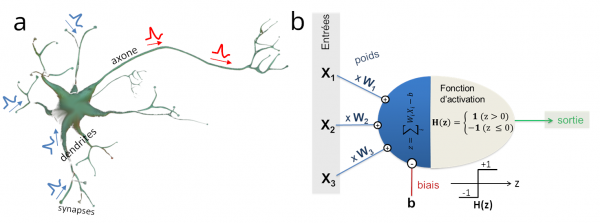
Figure 3 (a) Représentation schématique d’un neurone isolé (b) Shéma de principe d’un perceptron comprenant trois entrées X1, X2 et X3 (soit quatre paramètres : les poids synaptiques W1, W2 et W3 ainsi que le biais b)
Le perceptron a introduit la technique d’apprentissage supervisé en ajustant ses paramètres pour minimiser les erreurs sur un jeu de données dédié. Une fois les poids (Wi) et le biais (b) optimisés, le neurone artificiel devient opérationnel pour sa tâche de classification.
Cependant, la machine apprenante créée par Frank Rosenblatt pour la reconnaissance de formes simples a, malgré les promesses de puissance de son créateur, rapidement révélé ses limites ; elle ne permet de classifier que les données linéairement séparables, ce qui réduit considérablement son champ d’application.
Il faudra attendre l'avènement des réseaux de neurones pour dépasser cette contrainte, ainsi qu'une technique astucieuse pour ajuster en série leurs multiples paramètres (l'algorithme bien connu de la descente de gradient).
2.2. Conception d’un perceptron analogique
Pour réaliser les deux fonctions nécessaires à la fabrication d’un perceptron à partir de composants électroniques simples, il est assez naturel de penser à utiliser un amplificateur opérationnel (AO) en mode additionneur pour la première étape puis, pour la fonction d’activation, il est possible d’utiliser ce même composant en mode comparateur (comme illustré sur la figure 4).
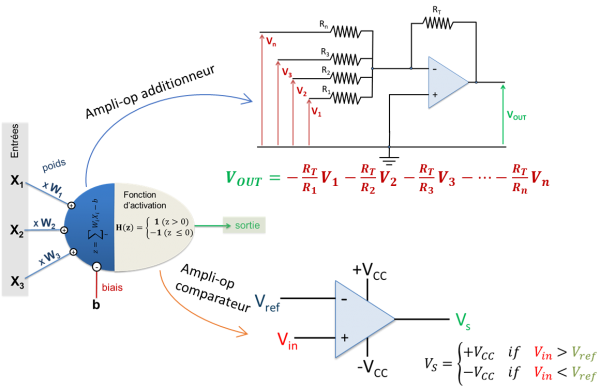
Figure 4 : Conception du perceptron à partir de composants électroniques analogiques simples (resistances ohmiques et amplificateurs opérationnels)
Ainsi, pour la partie additionneur des entrées du perceptron, le poids synaptique appliqué sur chaque entrée sera, au signe près, le rapport 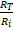 . Il suffira donc de modifier les valeurs de ces résistances pour ajuster les poids.
. Il suffira donc de modifier les valeurs de ces résistances pour ajuster les poids.
Pour la fonction seuil (fonction d’activation du neurone), si l’on prend la tension Vref = 0, donc l’entrée inverseuse de l’AO reliée à la masse, nous obtenons la fonction souhaitée.
Ainsi pour la fabrication de notre perceptron, nous n’utiliserons qu’un jeu de résistances classiques, des potentiomètres (pour ajuster les paramètres à travers la valeur de la résistance) et quelques AO alimentés par des piles 9V.
2.3. Apprentissage du perceptron pour différenier les chiens des chats…
A partir de notre base de données contenant les données morphologiques d’une population de chiens et de chats de races différentes (cf. annexe 1), nous avons choisi deux paramètres sans dimension : les ratios « longueur sur largeur du corps » et « longueur du corps hauteur au garrot » comme illustré sur la figure 5. Le caractère linéairement séparable des données apparait clairement sur la figure.
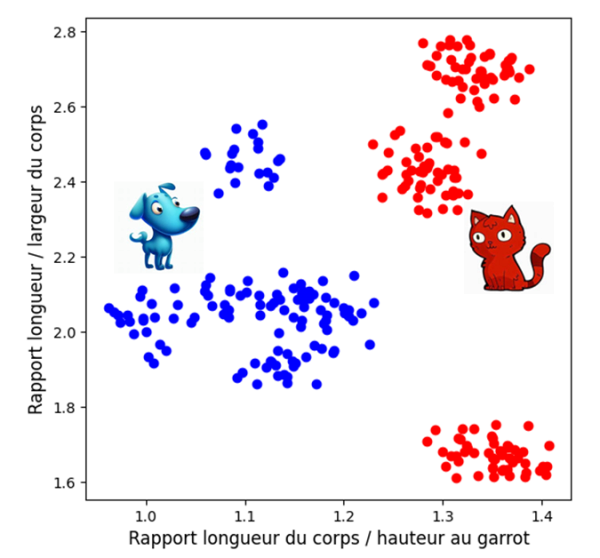
Figure 5 : Répartition des populations de chiens et de chats en fonction des deux paramètres adimentionnels choisis.
Ainsi le perceptron adapté à la résolution de notre problème de classification comporte deux entrées (les couples de valeurs des paramètres morphologiques retenus) et nécessite donc l’optimisation de trois paramètres, deux poids synaptiques (W1 et W2) et le biais (b).
- Note de bas de page 3 :
-
Le notebook jupyter du perceptron est disponible à l’adresse https://gitlab.xlim.fr/orlianges/perceptron-analogique.git
Pour réaliser l’apprentissage de notre perceptron, un court programme en langage « python » a été écrit puis exécuté sous la forme d’un « notebook jupyter »3 en travaillant sur une partie des données collectées (données d’apprentissage).
Dans l’algorithme utilisé (présenté en langage python dans l’annexe 2), l’estimation de l’erreur est réalisée en comparant la sortie du perceptron (« -1 » pour un chat et « +1 » pour un chien) avec la réponse connue de l’élément utilisé pendant la phase d’apprentissage. Ainsi de manière élégante, il suffit de s’intéresser au signe du produit de ces deux valeurs pour savoir si la classification chien/chat du perceptron est valable :
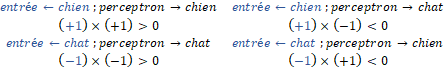
Après la phase d’apprentissage sur l’ensemble des données idoines, nous obtenons les résultats synthétisés sur la figure 6. Avec les paramètres ajustés du perceptron, il est possible de tracer sur le plan de représentation des données la droite de décision (en vert sur la figure 6-b).
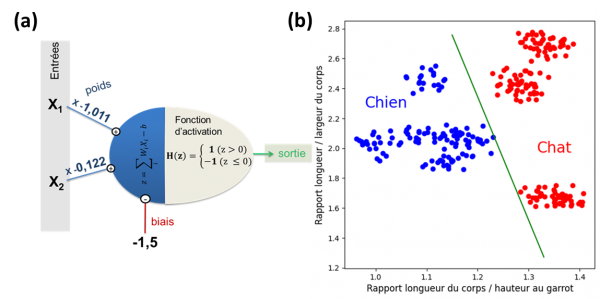
Figure 6-a Schéma du perceptron avec ses paramètres après apprentissage – b Droite de décision associée au perceptron après l’apprentissage, séparant les populations de chiens et de chats dans la même représentation graphique que sur la figure 5.
2.4. Construction et vérification du perceptron « chien / chat »
Connaissant les paramètres du perceptron, il est maintenant possible de choisir et d’ajuster les résistances du circuit à réaliser. Le schéma du circuit est présenté figure 7-a et sa réalisation sur la figure 7-b. Nous avons choisi d’utiliser une résistance Ra = 10k ainsi les potentiomètres de réglage du perceptron R1, R2 et Rd2 sont ajustés de façon à obtenir les valeurs suivantes :
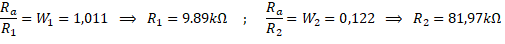
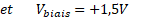
Le signal à la sortie du dernier AO du circuit, le comparateur, est positif s’il s’agit d’un chat et négatif dans le cas contraire. Deux LED de couleur respective verte et rouge ont donc été branchées sur la sortie en parallèle et dans des sens opposés pour s’allumer l’une ou l’autre suivant le sens du courant. Lorsqu’aux deux entrées de notre perceptron nous imposons des tensions V1 et V2 correspondant aux rapports morphologiques d’un chien, la LED verte s’allume (dans le cas d’un chat, la rouge prend le relai).
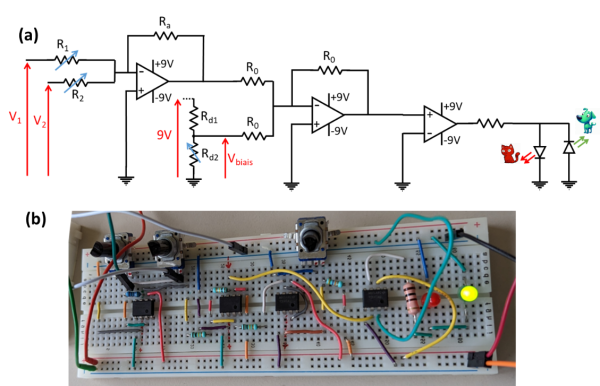
Figure 7-a Scéma du perceptron « chien/chat » - b Circuit réalisé sur une plaque d’étude, alimenté par deux piles de 9V, intégrant des AO, des résistances, des potentiomètres et deux diodes, l’une verte et l’autre rouge.
Après l’apprentissage sur une collection de 270 individus, il a été possible de vérifier la validité des réglages de notre perceptron avec 30 données non encore utilisées sans observer d’erreur.
Conclusion
Dans ce travail d’archéologie scientifique, nous avons pu faire revivre un fossile des début de l’intelligence artificielle, le perceptron monocouche. Nous avons travaillé sur une version analogique rudimentaire de ce dispositif fondateur sur lequel s’appuie encore l’IA moderne avec ses réseaux de neurones profonds comportant des millions d’unités. De même le choix de la nature de la classification de notre perceptron a été inspiré par l’usage historique de ce problème d’identification « chien ou chat », celui-ci étant toutefois directement réalisé sur des bases de données d’images dans ses versions modernes.
L’une des vertus de ce type de travail sur des systèmes physiques simples comme notre perceptron analogique est qu’il permet d’illustrer et de faciliter la compréhension du fonctionnement de systèmes plus complexes ; ainsi, le concept de mémoire sur ce type de dispositif est ici associé au choix et à l’ajustement des différentes valeurs de résistances du circuit (ici la position des différents potentiomètres). Cette mémoire est donc fondamentalement « intriquée » dans ces composants. Dans le cas de réseau de neurones, on appréhende ainsi plus facilement la notion de mémoire associée à un système parallèle distribué.
D’un point de vue pédagogique, ce travail pluridiciplinaire a aussi été concu pour être proposé à un public de lycéens scientifiques ou techniques en restant assez simple sur la partie électronique analogique et en privilégiant l’usage du langage « python » relativement bien implanté dans ces filières.
Dans les perspectives à ce travail, deux voies de poursuite sont envisagées :
-
L’automatisation de l’apprentissage directement sur le perceptron analogique
-
La réalisation d’un perceptron multicouche (réseau de perceptrons) ouvrant l’accès à des fonctionnalités plus évoluées